“Aprendizado automático nos permite construir soluções de software que superam o entendimento humano e mostram que a inteligência artificial pode inervar qualquer indústria” - Steve Jurvetson
Impressões Iniciais
Os algoritmos de agentes lógicos são ferramentas especialmente úteis para resolver problemas complexos em inteligência artificial. Somado a isso, tais algoritmos são utilizados em diversas tecnologias e domínios, tais como os Sistemas Especialistas e Big Data, evidenciando sua contribuir para o avanço da inteligência artificial em diversos domínios. Diante disso, o presente artigo tem como objetivo instruir o leitor um pouco mais sobre este universo.
Algoritmos de Agentes Lógicos: discussão, exemplo prático e implementação
Os algoritmos de agentes lógicos desempenham um papel crucial na inteligência artificial, permitindo que os agentes ajam de maneira informada e lógica em ambientes complexos. Eles são fundamentais para a representação, inferência e tomada de decisões em contextos nos quais a lógica desempenha um papel central. Tais algoritmos são projetados para representar conhecimento de maneira formal. Isso pode envolver a utilização de lógica proposicional ou de primeira ordem para expressar informações sobre o mundo em que o agente opera.
Por sua vez, os algoritmos de inferência lógica são implementados para permitir que agentes derivem novas informações a partir do conhecimento existente. Isso é crucial para a capacidade do agente de tomar decisões informadas com base em raciocínio lógico. Além disso, vale ressaltar que a lógica é frequentemente utilizada na tomada de decisões, permitindo que os agentes avaliem condições, estabeleçam metas e escolham ações com base em uma análise lógica do ambiente. Diante do exposto, confira um exemplo prático de algoritmo de agente lógico conhecido como Semantic Network.
Semantic network (Rede Semântica): Uma rede semântica é uma representação gráfica do conhecimento que utiliza nós e arestas para modelar relações semânticas entre conceitos. Cada nó representa um conceito, e as arestas indicam relações entre esses conceitos. Essas redes são usadas para capturar o significado e a interconexão de informações em um determinado domínio. Um bom exemplo é a rede de similaridade semântica de artigos de PNL (Programação Neurolinguística) desenvolvido pela engenheira eletrônica e de comunicação elétrica Anukriti Ranjan, cujo algoritmo pode ser visto a seguir. Por fim, a saída do código pode ser vista pela Imagem 1 logo em seguida.
Implementação da solução em python:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
"""
REF: https://towardsdatascience.com/semantic-similarity-networks-9aca31082d8e
Obs.: baixe as seguintes bibliotecas (pip3 para linux e pip para windows)
1) sentence_transformers
2) seaborn
3) bokeh
"""
from sentence_transformers import SentenceTransformer
import numpy as np
from sklearn.metrics import DistanceMetric
from sklearn.cluster import AgglomerativeClustering
import seaborn as sns
from bokeh.palettes import viridis
import networkx as nx
#document embeddings
embedder=SentenceTransformer('allenai/specter')
corpus=df_nlp_filtered['papers'].values.tolist()
corpus_embeddings = embedder.encode(corpus)
#distance measures
dist = DistanceMetric.get_metric('euclidean')
dist_scores=dist.pairwise(corpus_embeddings)
all_scores=dist_scores[np.triu_indices(dist_scores.shape[0], 1)]
#visualizing the distance measures
sns.set(rc={"figure.figsize":(12, 6)}) #width=12, #height=8
sns.histplot(all_scores,bins=100000)
#clustering
clustering = AgglomerativeClustering(n_clusters=None,affinity='euclidean',distance_threshold=25).fit(corpus_embeddings)
clusters = clustering.labels_
#np.unique(clusters).shape[0]
#get the list of papers corresponding to each cluster
idx_sort = np.argsort(clusters)
sorted_clusters = clusters[idx_sort]
# returns the unique values, the index of the first occurrence of a value, and the count for each element
vals, idx_start, count = np.unique(sorted_clusters, return_counts=True, return_index=True)
# splits the indices into separate arrays
clusters_split = np.split(idx_sort, idx_start[1:])
#create a dict which will be used as attribute for the network of nodes
color_options_clust=viridis(len(clusters_split))
cluster_num = {}
node_title = {}
color_clust={}
#Loop through each community in the network
for cluster_number, cluster in enumerate(clusters_split):
#For each member of the community, add their community number and a distinct color
for node in cluster:
if node not in cluster_num.keys():
cluster_num[node] = cluster_number
node_title[node] = df_nlp_filtered.iloc[node]['title']
color_clust[node] = color_options_clust[cluster_number]
#get a threshold for edges
avg_dist_score=np.zeros(len(clusters_split))
for j,clust in enumerate(clusters_split):
clust_dist_score=0
for i in range(len(clust)-1):
node1=clust[i]
node2=clust[i+1]
clust_dist_score+=dist_scores[node1][node2]
avg_dist_score[j]=clust_dist_score/len(clust)
threshold_graph=np.round(avg_dist_score.mean()+0*avg_dist_score.std(),2)
dist_scores_graph=dist_scores.copy()
dist_scores_graph[[dist_scores_graph <= threshold_graph]]=1
dist_scores_graph[[dist_scores_graph > threshold_graph]]=0
#create a network
G = nx.from_numpy_matrix(dist_scores_graph)
#add attributes
nx.set_node_attributes(G, cluster_num, 'cluster_num')
nx.set_node_attributes(G, node_title, 'node_title')
nx.set_node_attributes(G, color_clust, 'color_clust')
degrees = dict(nx.degree(G))
nx.set_node_attributes(G, name='degree', values=degrees)
#special functions for querying the network graph
def make_node_dict_for_cluster(cluster_num,clusters_split,G):
node_dict={}
for node in clusters_split[cluster_num]:
node_dict[node]={}
neighbors=[n for n in G.neighbors(node)]
neighbor_cluster=[G.nodes[n]['cluster_num'] for n in G.neighbors(node)]
node_dict[node]['neighbors']=np.array(neighbors)
node_dict[node]['neighbor_cluster']=np.array(neighbor_cluster)
return node_dict
def connections_with_cluster(node_dict,clust_num):
nodes=list(node_dict.keys())
clust_array=node_dict[nodes[0]]['neighbor_cluster']
node_array=node_dict[nodes[0]]['neighbors']
for node in nodes[1:]:
np.hstack([clust_array,node_dict[node]['neighbor_cluster']])
np.hstack([node_array,node_dict[node]['neighbors']])
return np.count_nonzero(clust_array == clust_num),np.unique(node_array[clust_array == clust_num])
#node dictionary for cluster 3
dict_node_3=make_node_dict_for_cluster(3,clusters_split,G)
#getting its relatedness with cluster 10
connections_with_cluster(dict_node_3,10)
#most central nodes of the network and least central
#(not to be confused with importance)
#it gives information on intra network connectedness
def get_most_central_nodes(G,clust_num,top_k,bottom_k=False,clusters_split=clusters_split):
G_new=G.subgraph(clusters_split[clust_num])
sorted_dict=dict(sorted(nx.closeness_centrality(G_new).items(), key=lambda item: item[1],reverse=True))
if bottom_k:
return list(sorted_dict.keys())[-top_k:]
return list(sorted_dict.keys())[0:top_k]
get_most_central_nodes(G,3,5,clusters_split=clusters_split)
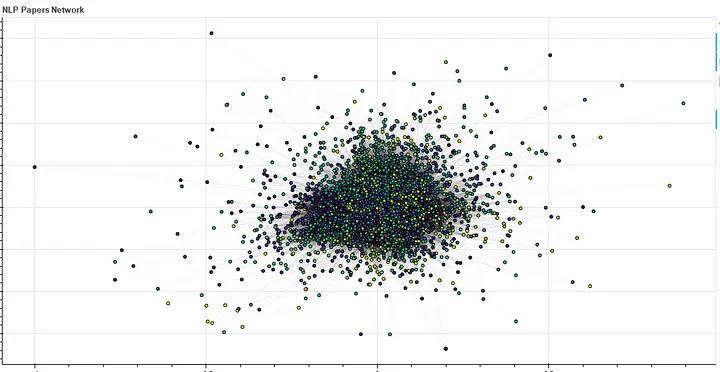
Ref.: Redes de Similaridade Semântica: Mineração de conhecimento a partir da interconectividade de documentos
Obs.: Os agentes lógicos, embora sejam poderosos em certas aplicações, apresentam algumas limitações, tais como complexidade computacional, dificuldade de manuseio de ambientes dinâmicos e problemas em compreender texto não estruturado.
Expansão do uso de agentes lógicos
Os agentes lógicos têm uma ampla variedade de aplicações em diferentes contextos devido a sua capacidade de representar conhecimento, realizar inferências e tomar decisões lógicas. Confira a seguir alguns exemplos de contextos de aplicação.
- Sistemas Especialistas: os agentes lógicos, devido a sua capacidade de representação do conhecimento por meio de regras lógicas,é particularmente útil em domínios específicos, como medicina e engenharia, onde a decisão baseada em lógica especializada é crucial.
- Jogos Inteligentes: agentes lógicos podem ser usados para criar NPCs (personagens não jogáveis) que simulem um jogador humano. Diante disso, esses personagens podem se adaptar ao ambiente do jogo e tomar decisões com base em regras pré-definidas. Jogos com StarCraft II: Wings of Liberty, League of Legends e Lichess são ótimos exemplos de aplicação de jogos onlines com NPCs inteligentes.
- Big Data: atividades como análise de dados e mineração de conhecimento podem utilizar agentes lógicos para identificar padrões, tendências e relações lógicas em conjuntos de dados complexos. Isso é especialmente valioso em áreas como machine learning e análise preditiva.
- Sistemas de Navegação Autônoma: em sistemas autônomos, agentes lógicos desempenham um papel vital na navegação segura. Eles interpretam dados de sensores, tomam decisões lógicas sobre direção e evitam obstáculos com base em algoritmos de inferência. Alguns bons exemplos de sistemas de navegação autônoma são os robôs autônomos fornecidos pela empresa Dynamic Robots e os carros autônomos de nível 2 fornecidos pela Tesla.
- Sistemas de Recomendação: em relação aos serviços de streaming e e-commerce, por exemplo, agentes lógicos podem analisar preferências passadas, comportamentos de compra e informações contextuais a fim de oferecer recomendações personalizadas para os usuários.
Conclusões
De acrodo com o exposto neste artigo, percebe-se que os agentes lógicos possuem um amplo domínio de aplicação, tais como sistemas especialistas, jogos, Big Data, etc. Por outro lado, a pesar de muito útil em divesos contextos, possui algumas limitações as quais devem ser ponderadas antes de utilizar tais ferramentas. Por fim, é possível inferir que, de acordo com sua ampla aplicabilidade e possíbilidade em lidar com problemas complexos, os agentes lógicos são extremamente impactantes para tecnologias de inteligência artificial, sendo este assunto de suma importância para a área.
Referências
SEMANTIC network. [S. l.], 7 nov. 2023. Disponível em: https://en.wikipedia.org/wiki/Semantic_network. Acesso em: 14 nov. 2023.
SEMANTIC Similarity Networks: Mining knowledge from inter-connectedness of documents. [S. l.], 22 set. 2022. Disponível em: https://towardsdatascience.com/semantic-similarity-networks-9aca31082d8e. Acesso em: 14 nov. 2023.